こんにちは。
今Deep Learningの論文紹介をやっているのですが、私が紹介しようかなと思った論文がKerasの作者でもある@fcholletさんのCVPRの論文でした。
It's official: my paper "Xception: Deep Learning with Depthwise Separable Convolutions" was accepted at CVPR. https://t.co/D876HseFDo
— François Chollet (@fchollet) 2017年3月4日
読む過程で調べた資料とかも凄くまとまっていたのですが、自分の勉強がてらまとめておこうと思います。
※あらかじめ言っておくと、ココに出ている元論文を全部隅から隅まで読んだわけではないのと、Deep Learning弱者なので、一部間違えている可能性があります(出来る限りおいましたが…)。もし見つけた方がいれば、ご指摘ください。
参考資料
読んだ資料とか参考になった資料は以下のとおりです。
◯実装
Xceptionは、既にkerasにも組み込まれているようで、以下から使い方が見れます。
論文の内容メモ
ここから論文の内容のメモです。
◯事前知識
■Convolutionの基本
論文を読む過程でConvolutionのパラメーター削減とかについて知る必要があります。以下の動画がイメージしやすくてわかりやすいです。
時間に余裕がある人は以下もみるといいかなと思います。
■1×1のConvolution
この論文では、「The Inception Hypothesis」に基いてネットワークを構築するんですが、その際に1×1のConvolutionについても知っておく必要があります。1×1のConvolutionではChannel方向(RGB方向とか)の畳み込みを行います。次元圧縮とかの意味合いで使われると表現されていることが多いと思います。
Introduction
論文では導入としてCNNの発展について触れられていました。
◯LeNet-style Model(1995)
一番最初のCNNのモデル。単純にConvolution層とMax poolingを用いて組んだNetwork。

◯AlexNet(2012)
上のLeNetを改良して出てきたのがAlexNet。convolutionが5層、fully-connectedな層が3つあるネットワークを構成。ImageNetのコンペで優勝したのもあり、Deep Learningがより注目を浴びるようになった。

◯VGG(2014)
AlexNetが登場してから、より層を深くすることがトレンドになった。そんな中で、ILSVRCのコンペで出てきたのが、VGG。よくfine tuningされたモデルをつかうときに出てくるネットワークなイメージです。
VGG16とVGG19があるが、いずれも層の数が16か19という理由で名前がついている。

◯GoogleNet | Inception V1/V2/V3/V4 (2015-2016)
VGGの次に出てきたのが、GoogleNet。Inception Moduleという概念がこれによって出てきた。
(画像の引用元)
Inception Moduleはマイナーな変更もあり、いくつかのバージョンが有る。現在はV1~V4まで出ている。
- Inception V1 | Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
- Inception V2/V3 | Szegedy, Christian, et al. "Rethinking the inception architecture for computer vision." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Inception V4 | Szegedy, Christian, et al. "Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning." AAAI. 2017.
Inception Moduleというのは、「Network In Network」という手法からインスパイアされたものとのこと。ざっくりとした雰囲気しか読んでないけど、通常の畳込み演算の途中に、更に多層パーセプトロンを加えたものらしいですね。

言われてみれば、ネットワークの中にフィルターをいれるというのは似ている。Inception Module自体についての説明は、次の部分でやります。
The Inception Hypothesis
ここからは完全に私の解釈も入っている(もちろん調査した上で書いてますが)ので、もしかしたら間違っているかもしれません。ご指摘ください。
◯Inception Module(V1)のそもそもの狙い
個人的にInceptionって映画は好きなんですが、なんか本当かわからないですけど、この映画から名前を取ったとか笑

一番最初にGoogleNetが出てきた時のInception Moduleの狙いは、こちらの解説サイトにあるように、大きく分けて次の2つがあると思います。
- フィルターのサイズで悩まなくていい(アンサンブル的な効果も期待できる?)
- 次元圧縮
一つ一つ見ていきます。
■フィルターのサイズ
これは自分でCNNに限らず、Deep Learningのモデルを組んだことのある方ならわかると思いますが、さもあたりまえに論文で設定されているいろんなパラメーターに対して、いざ自分で設定しようとすると、疑問が大量に出てきます。
フィルターのサイズについても同様で、正直どれがいいかわからないという問題があります。そこで、これをデータから学習させようと思うと、一番素直なのは「全部試してみて、その中で優劣を学習の過程で決めればいい」という考え方になると思います。

GoogleNetでは、この様々なフィルターを持ったModule、すなわち「Inception Module」を多段に重ねることで、各Module内のフィルターの学習と選択をやっていると考えることができます。
これについては、以下の動画が凄く参考になります。
また、複数のフィルターを用いることで、細部の表現だけでなく、より抽象的な表現の獲得も、一つのモジュール内で行うことが出来る、と解釈することもできます。
これが一つ目の理由です。
■次元圧縮
さて、ピュアなInception Moduleは上の画像で示したとおりなのですが、GoogleNetの論文でもこれではなく、以下のInception Moduleを用いることを推奨しています。

1×1のフィルターを大きなフィルターデアル5×5や3×3の前に入れています。少なくともこのGoogleNetが出た時点では、これは単純に次元圧縮の狙いを持ってやっています(のはずです。元論文をガッツリ読んだわけではないので…また論文ちゃんと読んで間違ってたら修正します)。
たとえば、28×28の画像があり、それに対して192channelの出力を前の層で出したとします。その時に、5×5のフィルターを32個使うとすると、次のような計算量になります(ストライド1でやっています)。
$$
192 * 5^2 * 28^2 * 32 = 120,422,400
$$
次に、1×1のフィルターを挟んだとします。その際に、16の出力を1×1のフィルターで出した後、5×5のフィルターをかけて、同じく32の出力を出したとします。その場合、次のような計算量になります。
$$
(192 * 1^2 * 28^2 * 16) + (5^2 * 28^2 * 16 * 32) = (2,408,448) + (10,035,200) = 12,443,648
$$
格段に計算量が減っていることがわかります。大規模なネットワークを作成した際に、一つ一つのモジュールで計算コストを減らせるのはメリットかなと思います。
これらが初期のGoogleNetの狙いでした。
◯The Inception Hypothesis
さて、論文の内容(肝)に移ります。まず普通の畳込み演算では何をしているかというと、当たり前といえば当たり前ですが、空間方向+channel方向の3次元を一度にあわせて畳み込んでいます。
では、Inception Moduleでは何をしているかを改めて見てみると、この空間方向の畳み込みとchannel方向の畳込みを分けて行っていると解釈することができます。
これを理解するために、「Pointwise Convolution」と「Depthwise Convolution」がわかっていたほうがいいので、それについてまず説明しようと思ったんですが、正直こちらの記事を読んだほうがいいと思ったので、もう詳しくはしません笑(ってか途中まで書いてこの記事の存在を思い出してマジ死にたくなった…けどめげない…)。
■Pointwise Convolution
これは、1×1のConvolutionのことです。1×1のConvolutionでは、channel方向のConvolutionのみを行います。
■Depthwise Convolution
これは、channel方向への畳込みを行わないConvolutionです。つまり、空間方向に対してのみ行います。
■Inception Moduleの仮説
Inception Moduleでは、先程説明したとおり、初期は上記のような理由で作っていたんですが、V3くらいからは通常の畳込みがやっている「空間方向+Channel方向」の畳み込みを、よりやりやすいような形で行うことを意識しています(と思います。V1でも既にできてちゃってたんじゃねとは思う笑)。

上は、Inception V3のModuleなのですが、これをみると、先程のPointwise Convolutionを行った後に、普通のConvolutionを行っています。
ここで、よりシンプルなバージョンのInception Moduleを考えてみます。

シンプルなInception Moduleをみるとよりわかりやすいんですが、このようにすることで、計算量が抑えられるだけではなく、Channel方向の畳込みをやった後に通常の畳込みをやったと解釈することができます。
普通の畳込みが一度にやるところを、Channel方向の畳み込みを先に少しやっておいて、その後普通の畳込みをやったと解釈できます。これにより、計算をより良く出来るようになっていると考えることができます。
さて、シンプルなバージョンのInception Moduleは、次のようにも表すことができます。以下は1×1で出力されたchannelに対して、3×3のconvolutionがオーバーラップせずにかけられているものです。

ここで、Xceptionの肝になる仮説が出てきます。それでは、「Inception仮説よりもはるかに強力な仮説を立て、クロスチャネル相関と空間相関を完全に別々にマッピングできると仮定することは合理的できるか?」ということです。
Xception Module("extreme" version of Inception Module)
先程のInception Moduleでゆるく仮定していたことというのを、より強く仮定して行おうというのが、Xception Moduleのやっていることです。

これは、Pointwise Convolutionをやった後に出力されたそのそれぞれのchannelに対して、Depthwise Convolutionをしようというものです。
先程説明したInception Moduleの仮定をより強くし、「Channlel方向の畳み込み」と「空間方向の畳込み」を完全に分離したもの、ととらえることができます。
◯Depthwise Separable Convolutionとの違い
Depthwise Separable Convolutionという非常によく似た手法もあります。それとの違いについても、論文中では触れられています。
- Depthwise Separable ConvolutionはDepthwise Convolutionをした後にPointwise Convolutionをしますが、XceptionではPointwise Convolutionを先に行います。
- Depthwise Separable Convolutionでは、Depthwise Convolutionをした後に非線形の活性化関数(ReLU)はいれませんが、Xceptionでは入れている。
著者は、一番最初の違いはそれほど重要ではなく(積み重ねたら順番なんて関係なくなっていくと考えて良い)、その次の部分が重要としています。ここについては実験で確かめています。
Prior Work
パラメーターの削減系の手法として、畳込みを工夫したものはいくつも提案されている。
◯Inception architectures
複数のバージョンがあるが、これらは、畳み込みを複数のブランチに因数分解してチャネル上で、次に空間上で連続的に動作させることの利点を最初に示した。
◯Depthwise separable convolutions
2012年よりも前にあったかもしれないんですが、2012年に出されたそうです。
その後、2013年にLaurent SifreがGoogle Brainのインターンシップ中にdepthwise separable convolutionを開発したそうです(マジカヨって感じ笑)。
この当時はAlexNetに適用して精度が少し良くなって、学習の収束の速度が劇的に早くなったのと同時に圧倒的にモデルサイズを削減したそうです。この研究はICLR 2014でも発表されたみたいです。
そのプレゼンの動画は以下。
その後、このDepthwise separable convolutionsはGoogleNetにも使われることになりました。MobileNetが登場したのはこの頃ですね。
◯MobileNet

こちらはあとでみるXceptionのArchitectureとは違い、完全にDepthwise separable convolutionでやったネットワーク。
アーキテクチャは以下の通り。

その他にもネットワークの軽量化については研究はされていますが、詳細は論文をどうぞ。
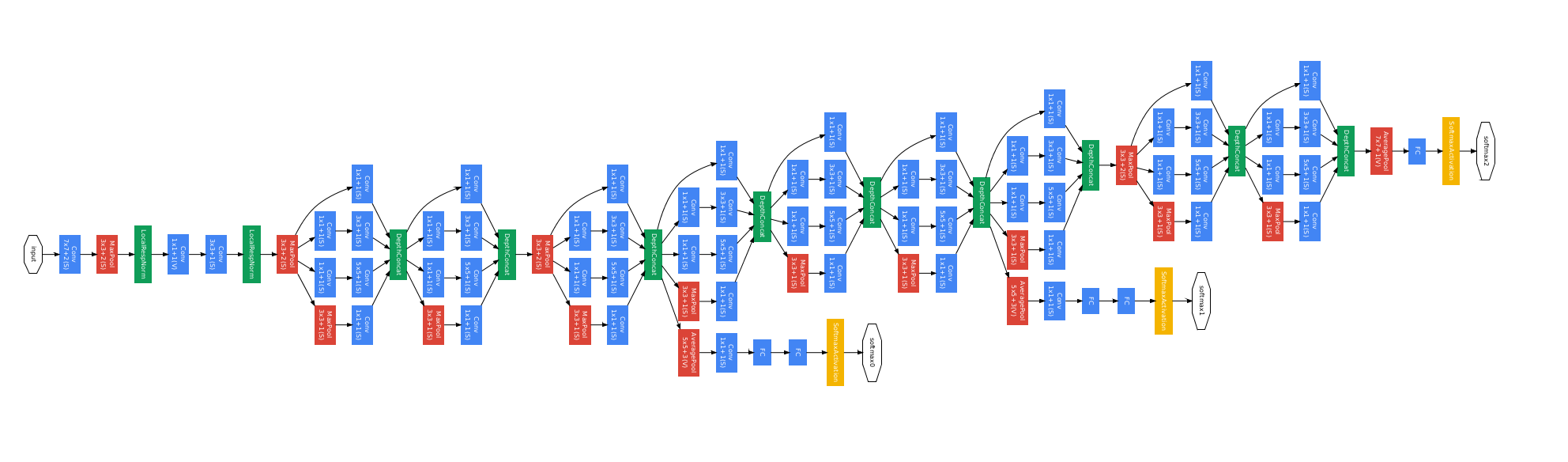
The Xception Architecture
Xception moduleを基本にしながら、Residual connectionsとDepthwise Convolutionを組み合わせています。全体で36層あります。

ネットワークがXception Moduleを積み上げた形になっているので、実装も凄く簡単だそう。実際にみると、すごく簡単だった笑。
既にkerasにも組み込まれているという驚きの速さ笑。
Experimentsと今後の展望
実験の結果は図をざーっとみたら、おぉなるほどだと思いますので、ここは割愛します。
以下のスライドの14ページからも解説が乗っているので、それをみるのもいいと思います。
www.slideshare.net
実験の結果と考察をまとめると以下のようなところがポイントになると思います。
- JFTとImageNetの両方でこれまでのベンチマークのものよりも精度があがった
- XceptionとInception V3では、同じパラメーター数で学習しているのに、精度がよくなったということは、より効率よくパラメーターを使えているということである。これは、channel方向と空間方向の分離が可能である、という仮説が正しかったことを示唆している。
- Inception Moduleでは、pointwiseとdepthwiseの間の非線形の活性化関数は重要であったが、今回のXceptionのように、完全にchannel方向と空間方向を別で畳み込みを行う場合は、間に非線形の活性化関数を入れないほうが良い。これは、deepな特徴空間では非線形な変換が必要だが、shallowなものでは(1channelのようなもの)、逆効果になるためと考えられる。
2つ目と3つ目は特に重要だなと思います。論文中ではResidual connectionsについても触れられていましたが、重要な知見と言えるまでの根拠がわからなかったので、省いています。
感想
こういうDeep系の論文は動きが早いので、一つの論文をじっくり読むと、それ以外のまとめみたいなのも知れるのはよかったです笑。
あと、Googleの内部事情?みたいなのも知れてよかった。なんとなく論文がゆるい雰囲気がして読んでいてよかった笑。